This text follows up on “Part 1: Motivation”, in which text I described why evaluating the improvements of a Serverless WebAssembly Runtime to Kubernetes and Distributed Workflow Engines is an exciting task.
In this post, I will describe what we want from the WebAssembly (Wasm) runtime and what that implies on the systems architecture and decisions yet to be made.
Requirements
The basic project idea was introduced in “Part 1: Motivation” in detail. Here, we recall the requirements in detail and propose two options how we could implement a system that does what we need.
Our main goal is to implement a serverless Wasm runtime for a cloud-native workflow engine.
This means that our solution must integrate and scale well in a distributed (cluster) setting. The end-user should be able to call Wasm-based remote functions just like local ones and the runtime implementation takes care of scaling, fault handling, etc.
We decided to focus on Kubernetes and the “Cloud-Native” ecosystem because of its popularity and open-source approach. OSS allows us to stand on the shoulders of giants and build our solution on top of the existing work of others in this field. This is why we aim at providing a Kubernetes-native solution that feels familiar to existing tools in this ecosystem.
The runtime must also integrate seamlessly with state-of-the-art workflow engines without the workflow engines having to incorporate implementation-specifics of Wasm modules and their distributed execution.
We cited efficiency improvements among security as a main motivation. Thus, we must ensure that latency (i.e., the time until a Wasm module executes) and runtime overhead (i.e., the resource that a single invocation requires) are minimized.
From an end user point-of-view, it is important that Wasm modules can be run reliably and failures can be easily diagnosed and fixed. This is why the runtime must ensure observability and maximize ecosystem-nativeness. Since I want to provide a usable end-to-end solution, the runtime must be able to offer APIs for interfacing with external systems, such as SQL databases, K/V stores, and RESTful APIs.
Systems Architecture
There are two approaches as to how one can implement the Wasm runtime for Kubernetes (K8s). The first one aims to be as native as possible by representing Wasm modules as Kubernetes Pods (Option A). The second one is built upon a more traditional three-tier application architecture (Option B).
In the following paragraphs, I will describe both options in more detail, show their pros & cons regarding our requirements and classify some existing software projects in the Wasm world into both categories.
Preferred Option: Wasm Modules as Pods
The first option treats Wasm modules as first-class citizens in the Kubernetes ecosystem. The runtime represents them as Pods.
Design
The Kubernetes documentation describes a Pod as the smallest deployable unit of computing in Kubernetes. Traditionally, Pods consist of one or more Linux containers who share storage and network resources and are scheduled onto the same physical machine (Node).
The K8s node agent would use a Wasm runtime instead of a container runtime implementation, but conceptually, that’s about it.
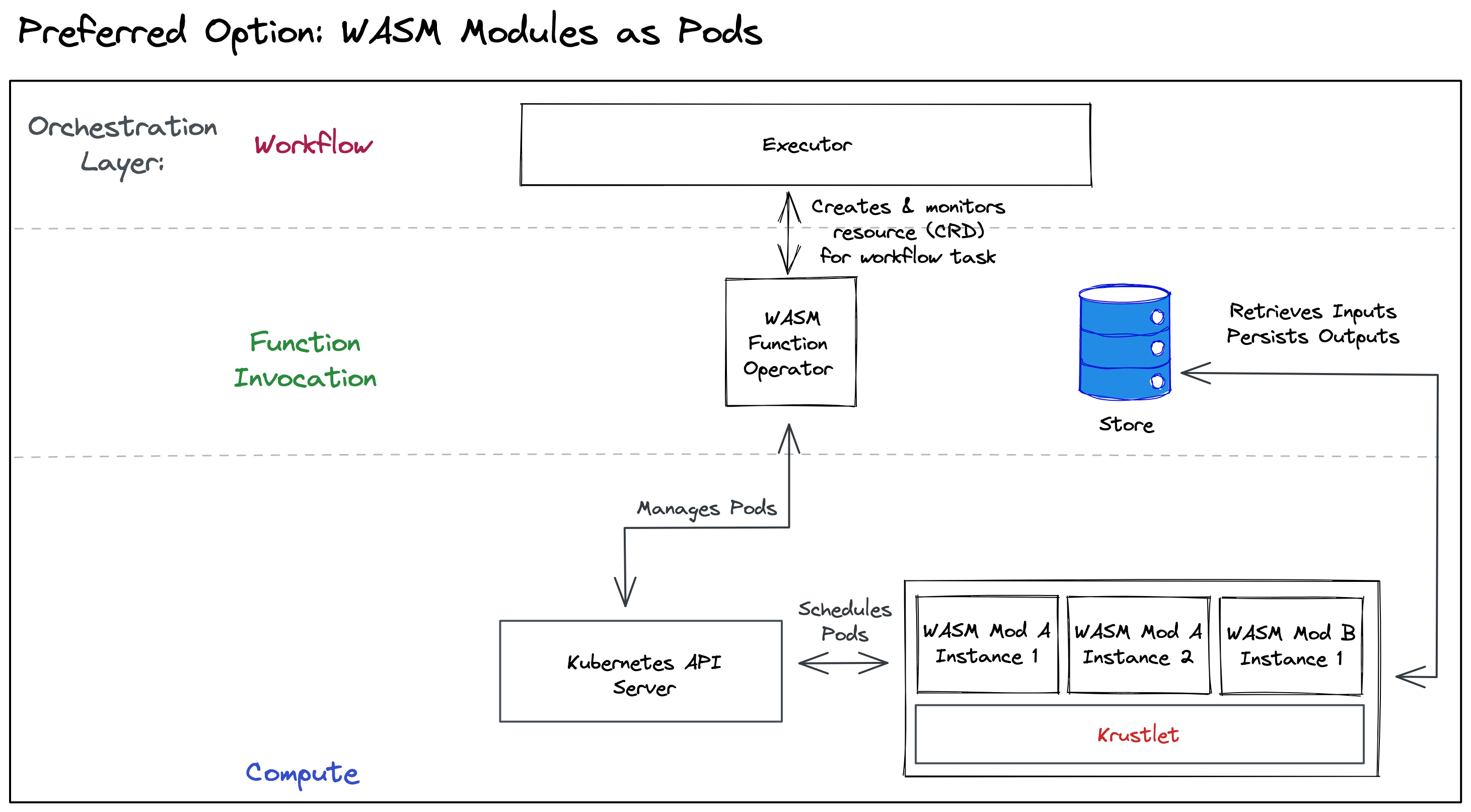
The above diagram depicts how this design allows the workflow executor to call Wasm modules through a custom operator. This operator manages the Wasm Pods. This includes fault handling and provisioning of input/output parameters & artifacts. It manages the Wasm Pods through the Kubernetes API. On the other side, we’d register one or more additional nodes to the cluster. These nodes execute the Wasm modules. In the diagram we show two implementation methods. The upper one uses the existing K8s Node implementation (Kubelet) and implements the Wasm-specifics at the Container Runtime Interface (CRI) level. The lower one directly implements the Node-related API commands (Krustlet).
🕵️♂️ Re-using the Kubelet would lower the implementation effort, but we do not yet know if the CRI API is at the right level of abstraction. An existing project chose not to go this route and we’d like to know why they made this choice.
Pros and Cons
The Wasm-as-Pod architecture has the benefit that it is based upon the proven cluster scheduling & resource management strategies from the Kubernetes implementation. Moreover, it would not need to contribute new tools for end users to manage and debug workloads (because existing tools to interact with the K8s API, such as kubectl). Moreover, when we integrate Wasm into the K8s resource (CRD) system, other people can reuse our work on the K8s API level (for example to use Wasm modules for an entirely different use case than workflows). Essentially, this allowed the Wasm runtime to “stand on the shoulders of giants”.
On the other hand, since every Wasm module invocation would go through K8s scheduling, we do not yet know huch much latency & computational overhead this adds. One of our project’s design goals is performance. This is why a high overhead could be detrimental.
Related Projects
Interestingly there is already a project which embeds Wasm modules as Pods into Kubernetes: Krustlet, which is already available on Azure AKS beta. This projects is included in the diagram above. They focus on simple stdin/stdout-based interaction (for example: WAGI, which runs Wasm modules CGI-style).Our solution for the “node” part could be based upon their existing work, but needed to be extended with more versatile input/output capabilities for parameters & artifacts.
With the Crossplane project, higher-level abstractions can be built on-top of K8s primitive resources. These abstractions are represented as Custom Resource Definitions (CRDs) in K8s, allowing their users to simplify K8s infrastructure development. This is conceptually close to the “custom operator” part of the design proposal.
Fallback Option: Three-Tier Web Service
The second design option is a more traditional approach that is a web service with a three-tier architecture. Essentially, it is a safe fallback from the fancier K8s-native solution.
Design
There is a RESTful web service with one (primary) use case: POST /invoke to invoke a Wasm module and return the results. The service invokes the Wasm modules directly in-process and takes care of fault handling. For a given level of parallelism, resource allocation & scaling is managed at the (web service) container level. For example, we could expose custom metrics measuring the service utilization and scale containers horizontally based upon this metric.
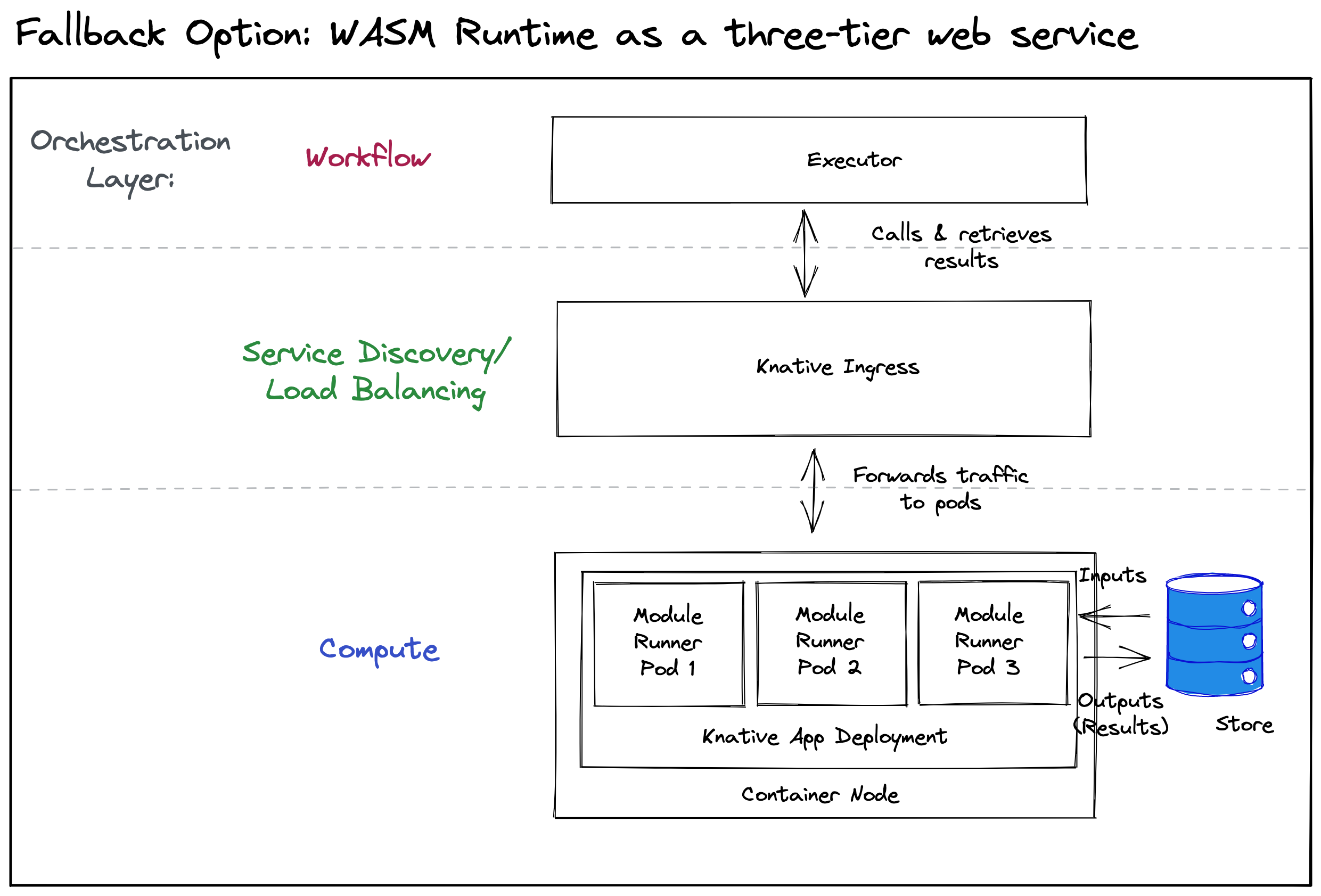
The diagram above this paragraph shows how this can be achieved with the Knative project which provides a Function-as-a-Service implementation for K8s. A Knative Ingress handles request distribution. The forwarded requests are handled by traditional container-based Pods that invoke the Wasm modules and return the results.
Pros and Cons
The most important benefit of this architecture is that it is low-risk. This is because it follows the same architecture as many web services and the only complexity is behind the Wasm module invocation handling itself. Compared to the first option, it also does not pose a risk of overhead in terms of latency and resources.
A neutral aspect is that it is independent from Kubernetes. This is what makes it applicable to other use cases and schedulers. But this is also what sets the need for a custom API and means for debugging and observability.
The downside is that the project is alien to any ecosystem and won’t allow us to explore how Wasm can be integrated into practical distributed systems in practice.
Related Projects
The faasm project describes itself as a “high-performance stateful serverless runtime”. It executes “faaslets” which execute code compiled to WebAssembly. Compared to our preferred architecture and Krustlet, they provide advanced features such as pre-warming modules (”proto-faaslets”) for higher performance. But faasm does not integrate into any orchestration system natively.
Knative is a Function-as-a-Service implementation for Kubernetes and could be used to deploy the web service.
Next Steps
The next step to de-risk the “Module as Pod” strategy is to evaluate the scheduling overhead of Kubernetes. A possible approach is using Kubernetes with three Kustlet nodes (for example), and benchmarking the time it takes Kubernetes to schedule a pod for a given level of parallelism.
Should we decide to follow this strategy, we would next decide whether to build upon Krustlet. I’d like to know the reasons not to adopt CRI. Apart from this, building upon Krustlet is compelling since it is an actively maintained project, not only with development support but also operational support on Azure.
Then there’s the choice for a Wasm runtime – where projects such as wasmer and wasmtime come into mind.
Finally, as Wasm is a very basic standard, an interface or function signature for the Wasm modules must be designed. Evaluating the Wasm Component Model and projects such as the waPC – WebAssembly Procedure Calls protocol is certainly an important task in this area that allowed us to follow the path of building on-top of [emerging] standards and tools.
Part 3 of this post series provides an overview of system design questions and a draft for an evaluation framework for the serverless Wasm runtime.